Calcular resúmenes de datos con dplyr::summarize()
14/12/2025
En el
tutorial de introducción a {dplyr} aprendimos a ordenar, seleccionar, y filtrar datos tabulares. Con estas operaciones básicas deberíamos poder desenvolvernos con tablas de datos.
Luego aprendimos a crear y modificar variables con
la función mutate() de {dplyr}.
Ahora veremos cómo calcular resúmenes de datos. Con esto nos referimos a tomar todas las observaciones o filas de una tabla, y aplicar algún cálculo para reducir todas las filas a un solo dato. Esto sirve, por ejemplo, para calcular la suma o el promedio de una columna, y para calcular estadísticos descriptivos.
library(dplyr)
options(scipen = 999) # desactivar notación científica
Introducción
Para este tutorial vamos a trabajar con datos de población de países de América del Sur, obtenidas desde una tabla de Wikipedia usando [web scraping](/tags/web-scraping/]. Puedes ver el código del web scraping aquí.
Para cargar los datos en tu entorno de R, ejecuta el siguiente código:
datos <- tribble(
~pais, ~superficie, ~poblacion, ~idh,
"Brasil", 8515767, 2.08e+08, 0.765,
"Argentina", 2780400, 44500000, 0.845,
"Perú", 1286216, 32200000, 0.777,
"Colombia", 1141748, 5e+07, 0.767,
"Bolivia", 1098581, 11200000, 0.718,
"Venezuela", 916445, 31800000, 0.711,
"Chile", 756102, 17800000, 0.851,
"Paraguay", 406752, 7100000, 0.728,
"Ecuador", 256370, 16900000, 0.759,
"Guyana", 214970, 8e+05, 0.682,
"Uruguay", 176215, 3500000, 0.817,
"Surinam", 163820, 5e+05, 0.738,
"Guayana Francesa", 83846, 3e+05, 0.901,
"Trinidad y Tobago", 5128, 1300000, 0.796
)
Como hemos visto en el
tutorial introductorio de R, para calcular una suma usamos la función sum():
total <- sum(datos$poblacion)
format(total, big.mark = ".", scientific = FALSE)
[1] "425.900.000"
Mientras que para calcular un promedio usamos la función mean():
promedio <- mean(datos$idh)
round(promedio, 2)
[1] 0.78
Cualquier función como las anteriores, que reciba varios datos y entregue uno solo, será una función que podemos usar dentro de summarize() para obtener resúmenes de datos.
Resumir datos con summarize()
La función summarize() calcula resúmenes de las tablas de datos, a partir de una o varias funciones que van a resumir los datos a una sola fila.
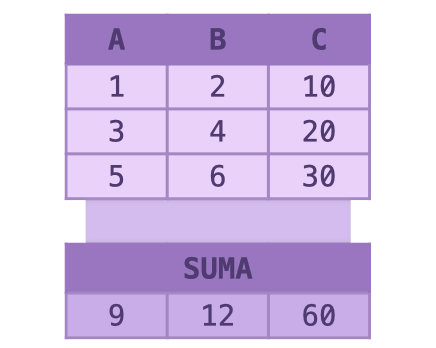
Para calcular el resumen de los valores de una variable, dentro de summarize() ubicamos la función necesaria, aplicada a la columna que nos interesa resumir.
Calculemos la suma (sum()) de la columna poblacion:
datos |>
summarize(
suma = sum(poblacion)
)
# A tibble: 1 × 1
suma
<dbl>
1 425900000
Redujimos las 14 filas de nuestra tabla de datos y obtuvimos una sola fila, que resume todos los valores de la poblacion a partir de una suma.
Dentro de summarize() podemos calcular varios resúmenes al mismo tiempo.
Agreguemos una segunda línea para calcular el promedio del índice de desarrollo humano (idh):
datos |>
summarize(
suma = sum(poblacion),
promedio = mean(idh)
)
# A tibble: 1 × 2
suma promedio
<dbl> <dbl>
1 425900000 0.775
Estadísticos descriptivos
De este modo podemos calcular datos que resumen las observaciones, por ejemplo, calcular estadísticas descriptivos relevantes a los datos que estamos trabajando:
datos |>
# calcular estadísticos descriptivos
summarize(
poblacion_total = sum(poblacion),
poblacion_promedio = mean(poblacion),
poblacion_minima = min(poblacion),
poblacion_maxima = max(poblacion)
) |>
# agregar puntos de miles
mutate(
across(
where(is.numeric), ~format(.x, big.mark = ".")
)
)
# A tibble: 1 × 4
poblacion_total poblacion_promedio poblacion_minima poblacion_maxima
<chr> <chr> <chr> <chr>
1 425.900.000 30.421.429 300.000 208.000.000
Resúmenes por grupos
Tal que como vimos con mutate(), podemos anteponer la función de agrupación group_by() para que los resúmenes de datos se calculen por grupos. Esto significa que, en vez de obtener una sola fila de resumen, obtendremos una fila por cada grupo de la variable que elijamos para agrupar los datos.
Primero creemos una variable que nos permita agrupar los datos:
datos_2 <- datos |>
# crear grupos por índice de desarrollo humano
mutate(grupo = case_when(poblacion >= 20000000 ~ "Alta",
poblacion >= 5000000 ~ "Media",
poblacion < 5000000 ~ "Baja")) |>
# ordenar factor
mutate(grupo = factor(grupo,
levels = c("Baja", "Media", "Alta")))
datos_2 |>
count(grupo)
# A tibble: 3 × 2
grupo n
<fct> <int>
1 Baja 5
2 Media 4
3 Alta 5
Ahora, usando group_by(), podemos calcular los resúmenes por cada grupo de población:
datos_2 |>
group_by(grupo) |>
summarize(
poblacion_total = sum(poblacion),
poblacion_promedio = mean(poblacion),
idh_promedio = mean(idh),
idh_maximo = max(idh)
)
# A tibble: 3 × 5
grupo poblacion_total poblacion_promedio idh_promedio idh_maximo
<fct> <dbl> <dbl> <dbl> <dbl>
1 Baja 6400000 1280000 0.787 0.901
2 Media 53000000 13250000 0.764 0.851
3 Alta 366500000 73300000 0.773 0.845
El uso de group_by() es muy conveniente, porque podemos tener un mismo código para calcular resúmenes estadísticos, y con tan solo cambiar la variable de agrupación obtendremos resultados actualizados.
Resúmenes de varias variables con across()
En lugar de tener que estar especificando las columnas que queremos resumir, podemos calcular un resumen para varias columnas al mismo tiempo.
Igual que con mutate(), esto lo logramos usando across() dentro de summarize(), que permite aplicar las operaciones a varias columnas a la vez.
Por ejemplo, para calcular un resumen de todas las columnas numéricas, indicamos dentro de across() que queremos aplicar la operación donde (where()) las variables sean numéricas (is.numeric):
datos_2 |>
summarize( # resumir los datos
across( # donde las columnas
where(is.numeric), # sean numéricas
~mean(.x) # calculando el promedio
)
)
# A tibble: 1 × 3
superficie poblacion idh
<dbl> <dbl> <dbl>
1 1271597. 30421429. 0.775
Para controlar el nombre que tendrán las columnas resultantes se puede usar el argumento .names:
datos_2 |>
summarise(
across(where(is.numeric),
~mean(.x),
.names = "resumen_{.col}_promedio" # cambiar el nombre de columnas
)
)
# A tibble: 1 × 3
resumen_superficie_promedio resumen_poblacion_promedio resumen_idh_promedio
<dbl> <dbl> <dbl>
1 1271597. 30421429. 0.775
O bien, se pueden poner las funciones de resumen dentro de una lista, donde puedes entregarle el nombre que tendrá el resultado:
datos_2 |>
summarise(
across(where(is.numeric),
list(
"promedio" = ~mean(.x)
)
)
)
# A tibble: 1 × 3
superficie_promedio poblacion_promedio idh_promedio
<dbl> <dbl> <dbl>
1 1271597. 30421429. 0.775
Múltiples resúmenes a la vez
También es posible calcular resúmenes usando más de una función, por ejemplo para calcular los promedios y las sumas al mismo tiempo, entregando las funciones dentro de una lista:
datos_2 |>
summarise(
across(where(is.numeric),
list(
"promedio" = ~mean(.x),
"suma" = ~sum(.x)
)
)
) |>
glimpse()
Rows: 1
Columns: 6
$ superficie_promedio <dbl> 1271597
$ superficie_suma <dbl> 17802360
$ poblacion_promedio <dbl> 30421429
$ poblacion_suma <dbl> 425900000
$ idh_promedio <dbl> 0.7753571
$ idh_suma <dbl> 10.855
O bien, podemos aprovechar across() para reducir el código que escribimos en combinación con resúmenes individuales:
datos_2 |>
summarize(
"idh_prom" = mean(idh),
across(c(superficie, poblacion),
list("suma" = ~sum(.x))
)
)
# A tibble: 1 × 3
idh_prom superficie_suma poblacion_suma
<dbl> <dbl> <dbl>
1 0.775 17802360 425900000
Obviamente podemos combinar lo anterior con la agrupación para obtener un completo resumen de datos de la tabla:
datos_2 |>
group_by(grupo) |>
summarise(
across(where(is.numeric),
list(
"promedio" = ~mean(.x),
"suma" = ~sum(.x)
)
)
)
# A tibble: 3 × 7
grupo superficie_promedio superficie_suma poblacion_promedio poblacion_suma
<fct> <dbl> <dbl> <dbl> <dbl>
1 Baja 128796. 643979 1280000 6400000
2 Media 629451. 2517805 13250000 53000000
3 Alta 2928115. 14640576 73300000 366500000
# ℹ 2 more variables: idh_promedio <dbl>, idh_suma <dbl>