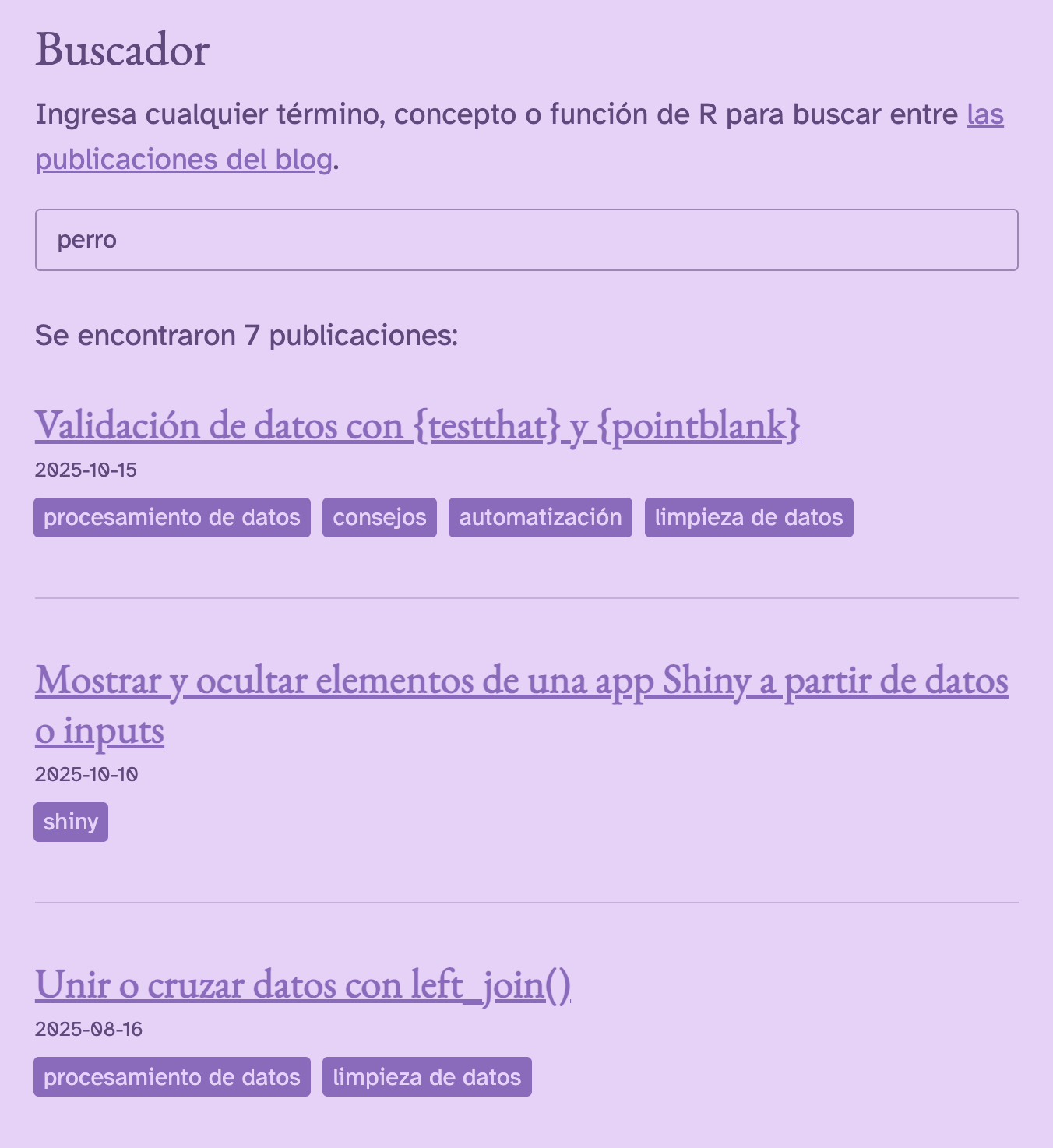
Desarrollando un buscador para mi blog con Shiny
11/11/2025
Índice
Este blog ya lleva más de 100 publicaciones! 🎉 y si bien uso las etiquetas para mantener todo organizado y ayudar a descubrir nuevos posts, a veces hasta a mi me cuesta encontrar publicaciones entre tanta cosa 😅
Por esa razón hace tiempo que quería implementar un buscador en este sitio, cosa que resultó ser más complicada de lo que esperaba. Pero lo logré, y estoy irracionalmente feliz por eso 💜
Algo hermoso de programar es la sensación de logro y orgullo que provoca poder crear cosas bonitas y que funcionan! ✨
Pero les cuento la historia. Pasa que lamentablemente1 decidí
hacer este blog con Hugo en vez de con Quarto, que recientemente se ha vuelto una
excelente herramienta para crear blogs y sitios web. Quarto
viene con buscador implementado, pero en Hugo había que implementarlo a mano. Y si bien encontré un tutorial muy completo para implementar búsquedas con LunrJS en Hugo,
era realmente larguísimo y complicado 😣 Así que me rendí.
Pero resulta que, cuando estaba intentando seguir ese tutorial, noté que en los primeros pasos se configuraba Hugo para generar un indice del blog en formato JSON. Un índice del sitio es un documento de texto que contiene todo el contenido de tu sitio web. El resto del tutorial era sobre usar ese índice para implementar la búsqueda. Entonces quedé pensando… 🤔
Después de semanas de darle vuelta a la frustración de no haberlo logrado, decidí hacerlo a mi manera, y me puse a hacer una app Shiny con R que usara el índice para buscar contenido y entregar resultados. ¿Qué tan difícil podía ser? 🫢
Resulta que nada de difícil. En menos de una hora ya tenía un producto funcional!
Generando el índice de búsqueda
El primer paso para el buscador fue hacer que mi blog generara un índice de su contenido para poder buscarlo. Esto que usualmente es complejo, porque implica instalar programas que se corren regularmente para re-generar el índice, con Hugo se hace facilito porque viene integrado en su forma de funcionar.
Ver código e instrucciones para crear el índice
Simplemente había que agregar al config.toml (archivo de configuración del sitio) que, además de HTML y XML, genere un output JSON del sitio. Luego, en una plantilla, decirle qué queremos que contenga el sitio.
En config.toml, agregar al final estas líneas:
[outputs]
home = ["HTML", "RSS", "JSON"]
page = ["HTML"]
Luego, crear un archivo index.json en la carpeta layouts para decirle que queremos que el JSON contenga título, enlace, fecha, etiquetas, y el texto completo de cada post:
{{- $.Scratch.Add "pagesIndex" slice -}}
{{- range $index, $page := .Site.Pages -}}
{{- if in (slice "post" "blog" "tutoriales") $page.Type -}}
{{- if gt (len $page.Content) 0 -}}
{{- $pageData := (dict "title" $page.Title "href" $page.Permalink "date" $page.Params.Date "tags" (delimit (default (slice) $page.Params.tags) " ; ") "content" $page.Plain) -}}
{{- $.Scratch.Add "pagesIndex" $pageData -}}
{{- end -}}
{{- end -}}
{{- end -}}
{{- $.Scratch.Get "pagesIndex" | jsonify -}}
Finalmente, reconstruimos el sitio ejecutando blogdown::build_site(). En la carpeta public va a aparecer el archivo index.json.
La gracia es que el índice se construye y actualiza solito, sin depender de otros programas ni instalar nada. Además, este índice queda expuesto a la internet, por lo que se puede acceder a él por la url https://bastianolea.rbind.io/index.json
Entonces, sin necesidad de web scraping ni APIs, podía hacer una app que leyera directamente los datos del sitio 😱
Obteniendo los datos del sitio
Empecé con las primeras pruebas.
Antes de hacer lo del índice JSON, primero empecé leyendo el índice XML, con el paquete {xml2} leía la dirección con read_xml(), y usando xml_find_all() iba apuntando a los elementos del índice para crear un dataframe. Pero pronto me di cuenta de que ese índice no tenía el texto completo de los posts, y tampoco leía el código de los posts.
Así que implementé el índice en JSON, y con el paquete {jsonlite} y la función fromJSON() pude obtener directamente un dataframe desde el índice, sin pasos intermedios como con la versión XML.
Así que hice una función procesar_json() que fue más o menos así:
obtener <- sitio |> jsonlite::fromJSON()
datos <- obtener |>
tibble() |>
mutate(texto = limpiar_html(texto)) |>
mutate(fecha = extraer_fechas(fecha)) |>
mutate(link = corregir_enlace(link))
Con esto ya tenía un dataframe con las más de 100 publicaciones.
Implementando la búsqueda
Existen muchos servicios y paquetes especializados en búsqueda… pero yo no soy informáticx ni quería complicarme. ¿Qué tan malo podía ser
usar {stringr} para detectar texto y hacerlo pasar por motor de búsqueda? 🤔
Resulta que nada de malo 😌 Los resultados de str_detect() no son para nada lentos, sobre todo cuando estamos hablando de apenas cientos de observaciones, cada una con apenas unas miles de palabras.
Así que implementar la búsqueda fue tan sencillo como:
busqueda <- "waldo"
resultado <- datos |>
filter(str_detect(texto, busqueda))
Y listo. Se obtiene el dataframe filtrado, limpio, bonito. Literalmente desde la obtención de los datos a los resultados de búsqueda en menos de 50 líneas de código. No hay mucho más que agregar, aguante R 😂
Actualización de algoritmo de búsqueda
Meses después cambié la búsqueda para usar el algoritmo BM25, que más allá de decir si un texto contiene o no el término de búsqueda, le entrega a cada elemento un puntaje con respecto al término de búsqueda, y así se pueden ordenar los resultados por relevancia. Más información en esta publicación.
Desarrollando la aplicación
En resumen, la app es básicamente:
- Un input de texto libre para las búsquedas con
textInput() - Un
reactive()que cargue los datos del índiceindex.jsonalojado en mi sitio - Otro
rective()que filtre estos datos en base al texto de búsqueda - Un output de texto que diga la cantidad de resultados
- Un output de HTML para los resultados construidos en base a los datos
- Amononar el UI de la app para que combine con mi sitio, usando
bs_theme()para encargarse del tema del sitio y una hoja de estilos CSS
Obtener datos desde la app
En la obtención de datos del sitio solamente puse la función procesar_json(). Esto implica, naturalmente, la carga (o descarga) del índice, que como tiene tanto texto puede pesar un par de megas.
Este sería el único *cuello de botella de la app, así que
le puse un bindCache() para que se guarden los resultados en la app, acelerando la carga del índice y disminuyendo el impacto en el servidor del sitio, y le puse que el cache durara una hora (usando como llave del cache la fecha/hora del día redondeada a la hora con floor_date())
# obtener datos del sitio
sitio <- reactive({
message("obteniendo sitio...")
procesar_json("https://bastianolea.rbind.io/index.json")
}) |>
# guardar cache por hora
bindCache(floor_date(now(), unit = "hours"))
Búsqueda desde la app
La búsqueda es literal un filter(str_detect(texto, input$busqueda)), que retorna un objeto reactivo con el dataframe filtrado por las coincidencias.
Se pone un debounce() para que lo que el usuario escriba no se busque a cada rato, sino que se esperen que el input se quede quieto 300 milisegundos antes de empezar la búsqueda.
Para el texto de los resultados usé cli::pluralize() para
escribir texto singular o plural automáticamente:
pluralize("Se encontr{?ó/aron} {n} publicaci{?ón/ones}:")
Salida de los resultados de búsqueda
Finalmente, teniendo un dataframe con los resultados de búsqueda, no puedo solamente mostrar una tabla con títulos y enlaces. Así que viene la parte más compleja: generar el código HTML en base a los datos para mostrar los resultados de búsqueda con una interfaz personalizada.
Se trata de un output de HTML, que naturalmente requiere (req()) que el usuario haya buscado algo y existan resultados:
output$resultados <- renderUI({
req(termino() != "")
req(n_resultados() > 0)
...
})
Luego, mi truco (o mala práctica?) favorito: separar un dataframe por filas para meterlas a un loop de purrr::map():
# separar resultados
elementos <- busqueda() |>
mutate(id = row_number()) |>
split(~id)
Con este código conviertes un dataframe en una lista donde cada elemento de la lista es un dataframe de una fila.
Entonces, por cada resultado de búsqueda (un elemento de la lista que contiene una fila del dataframe), lo metemos a una función donde definimos qué hacemos con las variables asociadas a cada resultado.

En el siguiente loop, cada elemento de los resultados se llama elemento, y como es un dataframe de una fila, con $ extraemos sus variables como titulo, link, etc., y las vamos ubicando libremente en un div():
map(elementos, \(elemento) {
div(class = "resultado",
# título con link
a(href = elemento$link,
target = "_blank",
h3(elemento$titulo)),
# fecha
div(class = "fecha",
elemento$fecha),
# etiquetas con links
div(class = "contenedor_etiquetas",
etiquetas(elemento$tags)),
# separador
hr()
)
})
Me gusta esta forma de hacerlo, porque es como llegar al código HTML con un dataframe de una fila y varias columnas, básicamente una lista con varios elementos, y voy decidiendo qué hago con cada elemento en la interfaz que va a crearse. Es como mezclar el UI y el server de Shiny en un mismo proceso.
La única parte complicada de esto es el código para las etiquetas o tags, que como pueden ser más de una, creé la función etiquetas() para ponerlas como rectangulitos una al lado de la otra:
Ver código
# texto de etiquetas separado por punto y comas
etiquetas <- function(tag) {
elementos <- tag |>
# separar porque es un puro texto delimitado por ";"
str_split(";") |>
unlist() |>
# eliminar espacios entre términos
str_trim()
# por cada elemento, crear un <div> con el texto y un enlace
map(elementos,
~div(class = "etiquetas",
# enlace
a(
div(.x, class = "texto_etiquetas"),
href = paste0("https://bastianolea.rbind.io/tags/",
str_replace_all(.x, " ", "-")),
target = "_blank")
))
}

Apariencia de la app
Ninguna aplicación sería nada si no cuidamos su apartado estético. En la interfaz de la aplicación primero
definimos un tema de colores y tipografías con {bslib}:
# tema
theme = bs_theme(
fg = "#553A74",
bg = "#EAD1FA",
primary = "#6E3A98",
font_scale = 1.1,
base_font = font_google("Atkinson Hyperlegible"),
heading_font = font_google("EB Garamond"),
)
Luego podemos afinar los detalles con una hoja de estilos CSS. CSS es el lenguaje usado para definir la apariencia de toda página web. Esto es un archivo styles.css que cargamos a la interfaz de la app con includeCSS("styles.css").
Mientras hacemos la interfaz de la app, ya sea en UI o dentro de una función como el map() que vimos antes, cuando definimos un div(), en el argumento class creamos clases CSS que luego usaremos para hacer que cada elemento tenga la apariencia deseada en styles.css.
Entonces, en la hoja de estilo le damos apariencia a las clases que fuimos creando en la app, por ejemplo:
/* estilo de título de resultados */
h3 {
color: #9069C0;
font-size: 24px;
font-weight: 700;
}
/* estilo de textos de fechas */
.fecha {
font-size: 12px;
margin-bottom: 4px;
margin-top: -4px;
}
Finalmente afinamos un detallito de la app: con
el paquete {shinydisconnect} de Dean Attali podemos personalizar el mensaje de desconexión de la app para que les usaries entiendan mejor que la app requiere recargarse.
# mensaje en caso de desconexión
disconnectMessage(
background = "#EAD1FA", colour = "#553A74",
refreshColour = "#9069C0", overlayColour = "#553A74",
size = 14,
text = "La aplicación se desconectó. Vuelve a cargar la página.",
refresh = "Volver a cargar"
),
Esto pasa porque, como las apps Shiny tienen un servidor detrás, no pueden estar conectadas por siempre, y luego de un tiempo de inactividad se desconectan. Por ejemplo, si el usuario de la app se va a un resultado de búsqueda y después aprieta atrás en el navegador, la app podría haberse desconectado al detectar que el usuario se fue.
Conclusión
Acabo de contar, y en total (app.R + funciones.R) la app tiene exactamente 300 líneas de código, que
puedes trajinear en su repositorio. Me alegra mucho haber resuelto tan rápido este problema que tenía con el sitio, y el resultado se ve lindo y es funcional 🥰
Si llegaste hasta aquí leyendo, muchas gracias 💜 Anímate a aprender a programar para que también hagas cosas útiles y bonitas!
-
Muchxs usuarixs de R están migrando sus blogs Hugo Apéro a Quarto, principalmente porque Quarto tiene muchas más funcionalidades integradas y permite hacer blogs con códgio de R con muchísimas cosas que Hugo no tiene, como pestañas, notas al margen, estilos y más. ↩︎