Etiquetas de texto que se repelen entre sí con {ggrepel}
11/7/2025
En este post veremos a agregar textos que se distancian entre sí automáticamente a tus gráficos. Esto sirve, por ejemplo, para mejorar visualizaciones de datos a las que queremos agregarle texto que identifique las observaciones, aún cuando las observaciones son demasiadas como para etiquetarlas a todas.
Usaremos el
paquete de R {ggrepel} para etiquetar puntos en un gráfico con textos que se repelen entre sí de forma automática.
Datos
A modo de ejemplo, usaremos datos del plebiscito de entrada de 2020 en Chile, obtenidos desde el repositorio de datos sobre los plebiscitos constitucionales. Éste repositorio, parte de mi mini sitio de datos sociales chilenos, ofrece versiones limpias y listas para usar de los resultados electorales de estos procesos.
library(arrow)
plebiscito <- read_parquet("https://github.com/bastianolea/plebiscitos_chile/raw/main/datos/plebiscito_2020_comunas.parquet")
Como los datos están alojados en el repositorio, pueden cargarse directamente en tu sesión de R tan sólo cargándolos desde el enlace anterior, sin necesidad de descargarse en tu computador.
Los datos vienen con cada fila representando una opción de voto por comuna del país, con su respectiva cantidad de votos, y se ven así:
library(dplyr)
head(plebiscito)
# A tibble: 6 × 6
cut_region region cut_comuna comuna opciones votos
<int> <chr> <int> <chr> <chr> <dbl>
1 1 Tarapacá 1101 Iquique Apruebo 61103
2 1 Tarapacá 1101 Iquique Rechazo 18879
3 1 Tarapacá 1101 Iquique Votos En Blanco 114
4 1 Tarapacá 1101 Iquique Votos Nulos 275
5 1 Tarapacá 1107 Alto Hospicio Apruebo 21589
6 1 Tarapacá 1107 Alto Hospicio Rechazo 4534
Procesamiento
Vamos a hacer un
gráfico de dispersión con {ggplot2}, para el cual necesitamos dos columnas con las dos opciones de voto: apruebo y rechazo. Como en el conjunto de datos que cargamos las opciones vienen en una columna (opciones), y el conteo viene en otra (votos), transformaremos la estructura de los datos a un formato ancho usando pivot_wider():
library(tidyr)
plebiscito_ancho <- plebiscito |>
pivot_wider(names_from = opciones, values_from = votos) |>
janitor::clean_names()
Lo que hizo pivot_wider() fue a usar la variable opciones para crear nuevas columnas, y la variable votos para rellenar las nuevas columnas con valores. De este modo, nuestros datos pasaron del formato largo al formato ancho, con una columna que contiene los votos del apruebo y otra del rechazo:
head(plebiscito_ancho)
# A tibble: 6 × 8
cut_region region cut_comuna comuna apruebo rechazo votos_en_blanco
<int> <chr> <int> <chr> <dbl> <dbl> <dbl>
1 1 Tarapacá 1101 Iquique 61103 18879 114
2 1 Tarapacá 1107 Alto Hospicio 21589 4534 37
3 1 Tarapacá 1401 Pozo Almonte 3730 1076 11
4 1 Tarapacá 1402 Camiña 293 207 2
5 1 Tarapacá 1403 Colchane 131 374 3
6 1 Tarapacá 1404 Huara 1136 379 6
# ℹ 1 more variable: votos_nulos <dbl>
Ahora usaremos {dplyr} para calcular qué opción ganó en cada comuna del país, y el porcentaje de votos que obtuvo:
library(dplyr)
plebiscito_comunas <- plebiscito_ancho |>
group_by(cut_comuna) |>
# calcular resultado final
mutate(resultado = case_when(apruebo > rechazo ~ "Apruebo",
rechazo >= apruebo ~ "Rechazo"),
.before = apruebo) |>
# calcular porcentaje de votos
mutate(porcentaje = apruebo/(apruebo+rechazo)) |>
ungroup()
head(plebiscito_comunas)
# A tibble: 6 × 10
cut_region region cut_comuna comuna resultado apruebo rechazo votos_en_blanco
<int> <chr> <int> <chr> <chr> <dbl> <dbl> <dbl>
1 1 Tarapa… 1101 Iquiq… Apruebo 61103 18879 114
2 1 Tarapa… 1107 Alto … Apruebo 21589 4534 37
3 1 Tarapa… 1401 Pozo … Apruebo 3730 1076 11
4 1 Tarapa… 1402 Camiña Apruebo 293 207 2
5 1 Tarapa… 1403 Colch… Rechazo 131 374 3
6 1 Tarapa… 1404 Huara Apruebo 1136 379 6
# ℹ 2 more variables: votos_nulos <dbl>, porcentaje <dbl>
Gráfico
Para realizar un gráfico de densidad, y especificamos las dos variables que pondremos en los ejes x e y, y una variable que representará el color de cada observación, las cuales se visualizarán como puntos usando geom_point():
library(ggplot2)
plebiscito_comunas |>
ggplot() +
aes(rechazo, apruebo, color = resultado) +
geom_point()
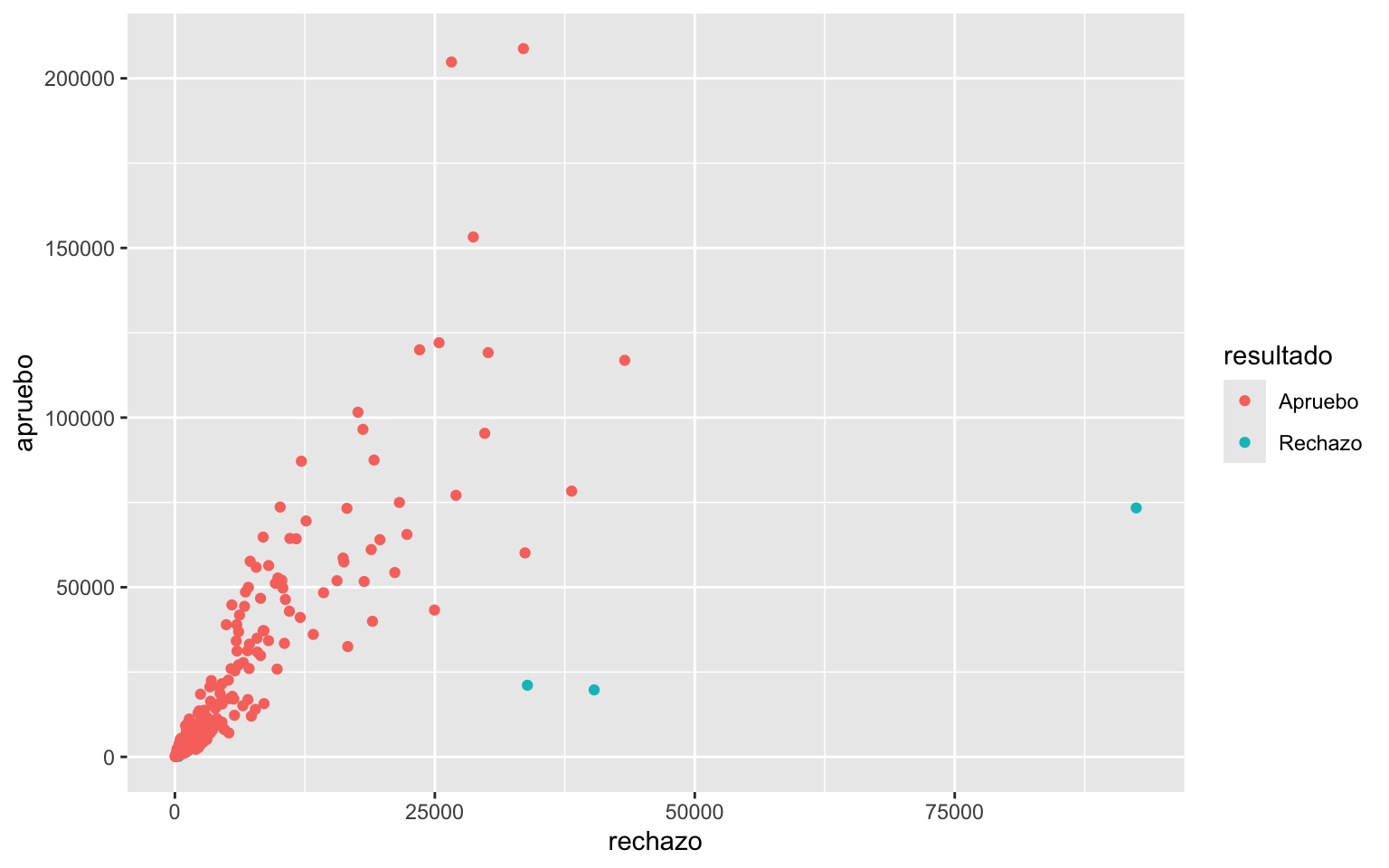
Ahora mejoraremos un poco el gráfico anterior: definiremos el formato de los números de las escalas con scales::number_options(), ajustaremos el tamaño transparencia de los puntos de geom_point(), luego aplicaremos escalas numéricas más bonitas con scale_{x}_continuous(), y finalmente ajustaremos un poco el tema y textos del gráfico:
library(scales)
# formato de números
number_options(decimal.mark = ",", big.mark = ".")
grafico_resultado <- plebiscito_comunas |>
ggplot() +
aes(rechazo, apruebo, color = resultado) +
geom_point(size = 3, alpha = 0.5) +
scale_x_continuous(labels = label_number()) +
scale_y_continuous(labels = label_number()) +
theme_minimal() +
theme(legend.text = element_text(margin = margin(l = 2))) +
labs(x = "Rechazo", y = "Apruebo", color = "Resultado")
grafico_resultado
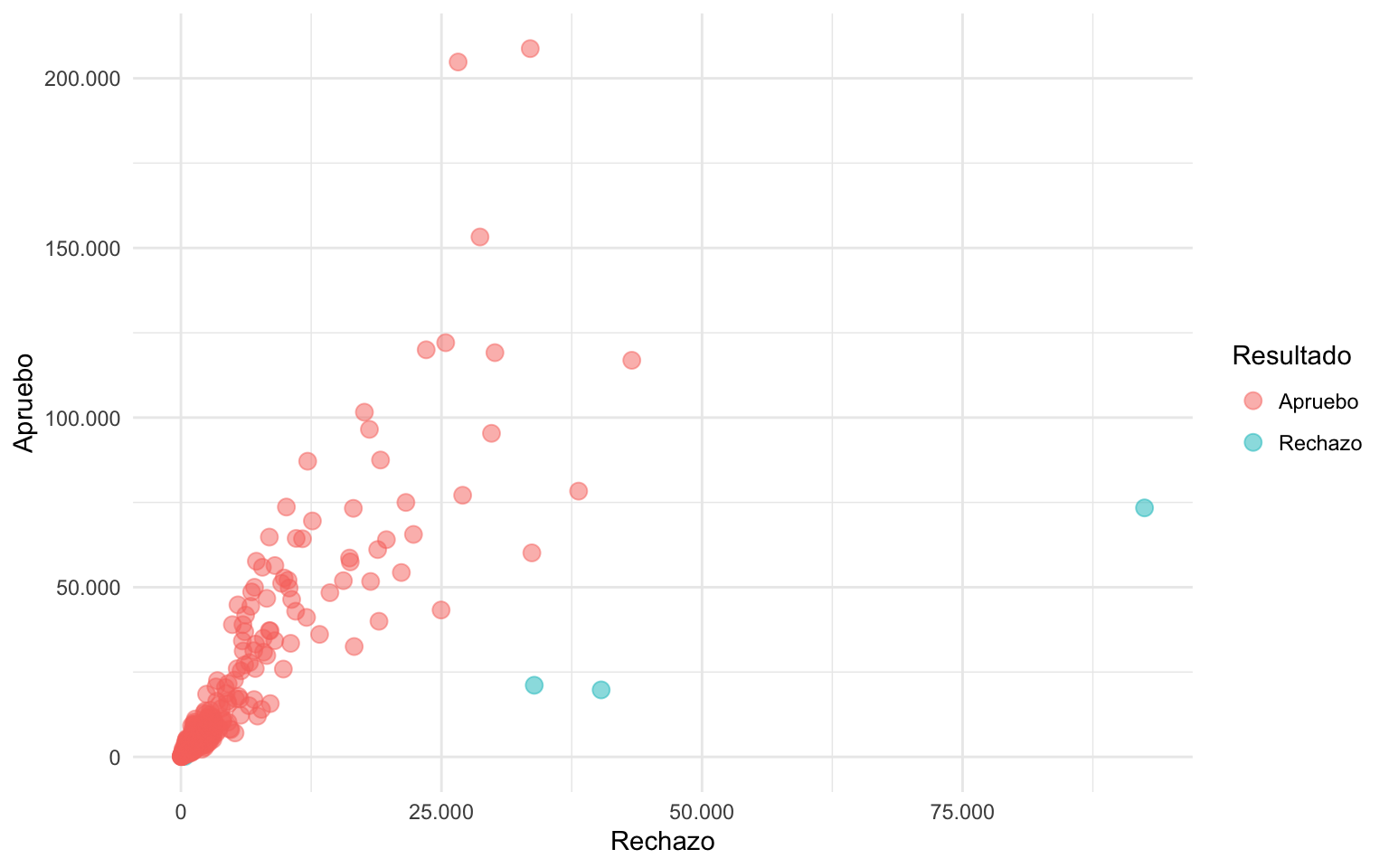
Ahora, al gráfico anterior, le agregaremos inocentemente etiquetas de texto a cada punto, a ver qué pasa:
grafico_resultado +
geom_text(aes(label = comuna), size = 2, color = "grey30", hjust = 0)
Absolutamente nefasto. Son tantos puntos que los textos se transforman en una masa gris debido a la concentración.
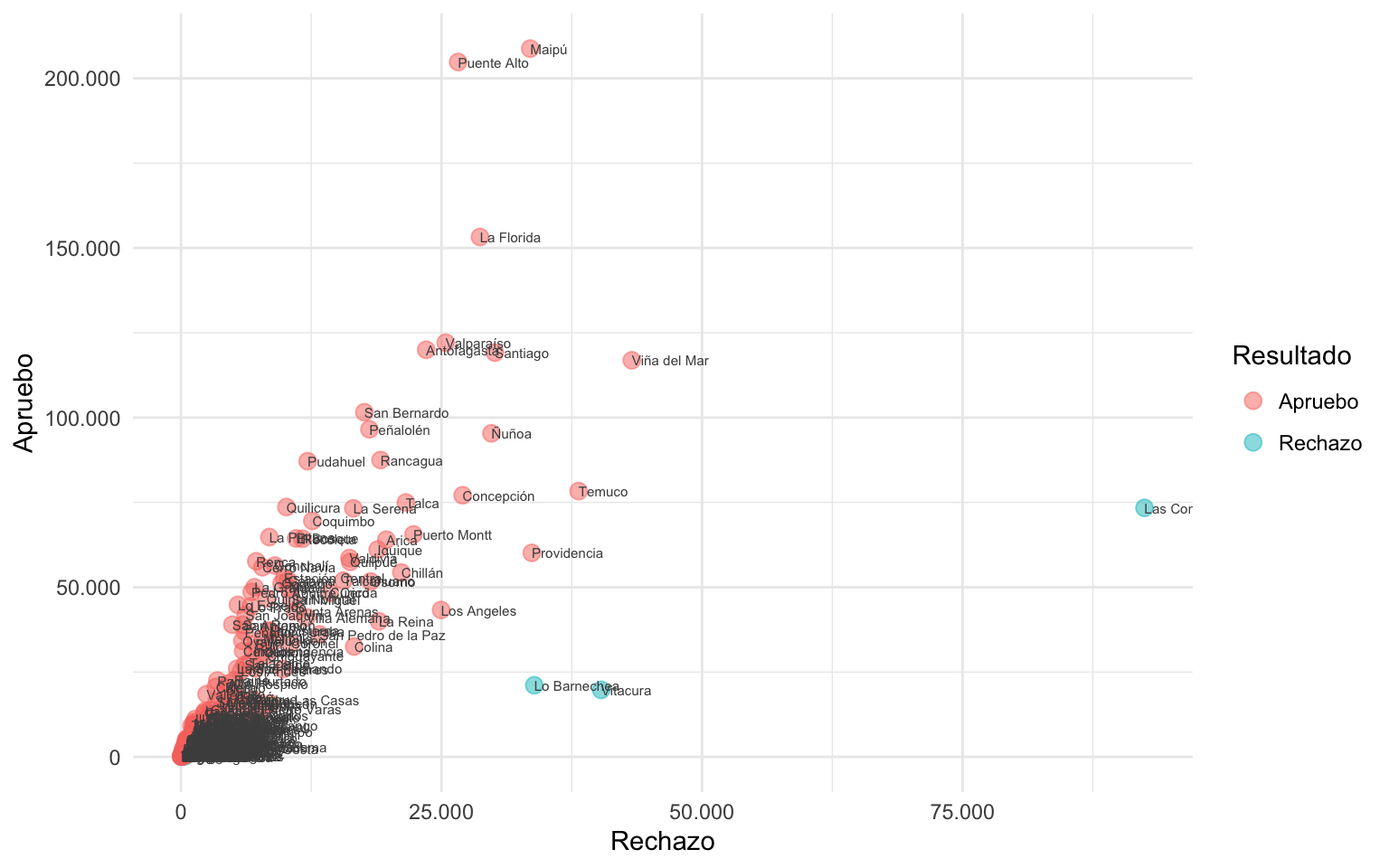
Un intento desesperado de corregir esto podría ser el argumento check_overlap, eliminará los textos que aparezcan encima de otros:
grafico_resultado +
geom_text(aes(label = comuna), size = 2, color = "grey30", hjust = 0,
check_overlap = TRUE)
Sin embargo, esta solución es demasiado básica, y aún hay textos que aparece encima de puntos, o fuera del margen del gráfico.
En estos casos resulta ideal geom_text_repel() como reemplazo de geom_text():
library(ggrepel)
grafico_resultado +
geom_text_repel(aes(label = comuna), size = 2.5, color = "grey30",
point.padding = 2 # margen de cada punto
)
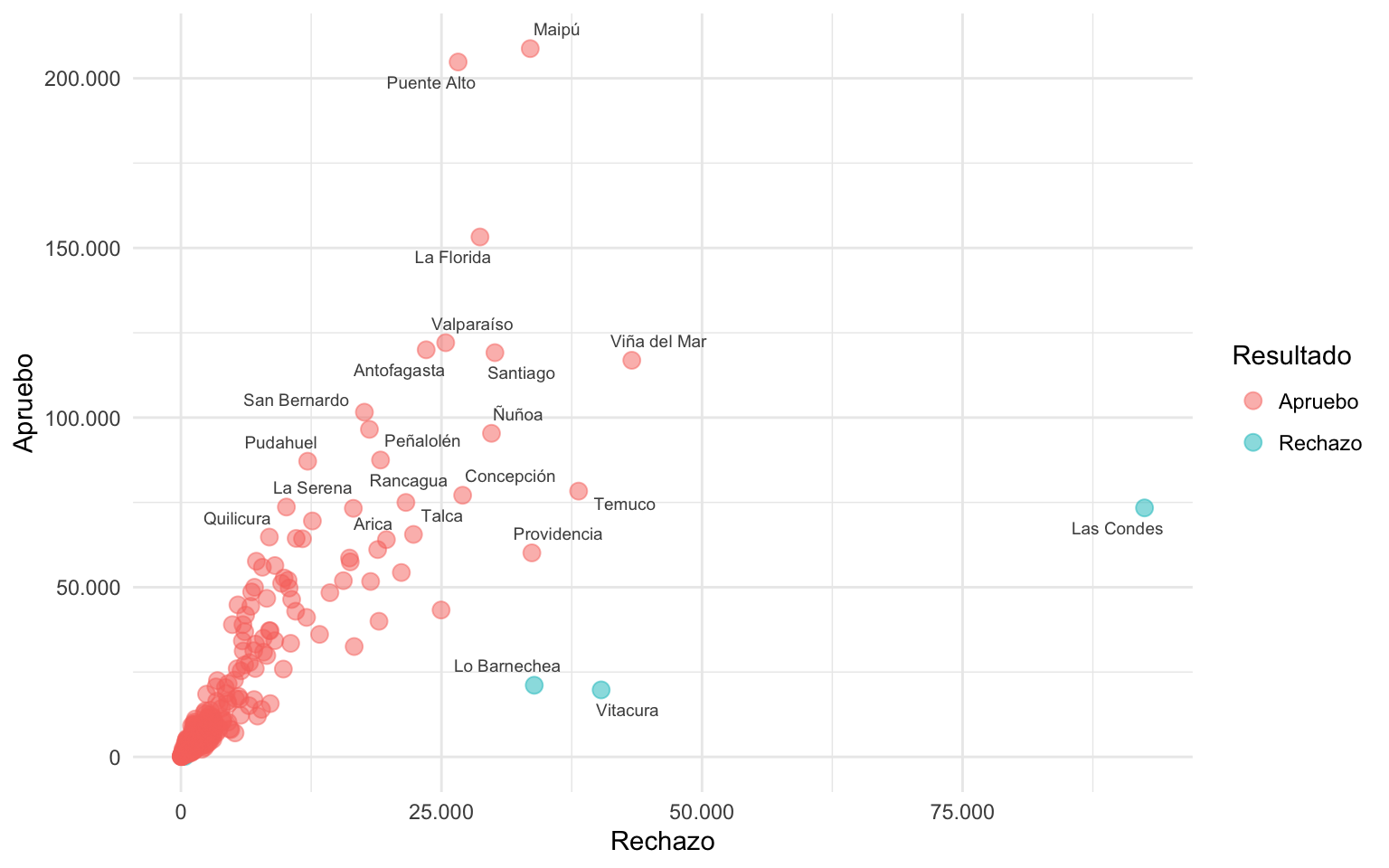
La función geom_text_repel() calcula la posesión de las etiquetas de texto con respecto a las demás, y decide el posicionamiento óptimo para que la mayor cantidad de textos aparezcan, sin que salgan encima de otros textos, ni encima de los puntos.
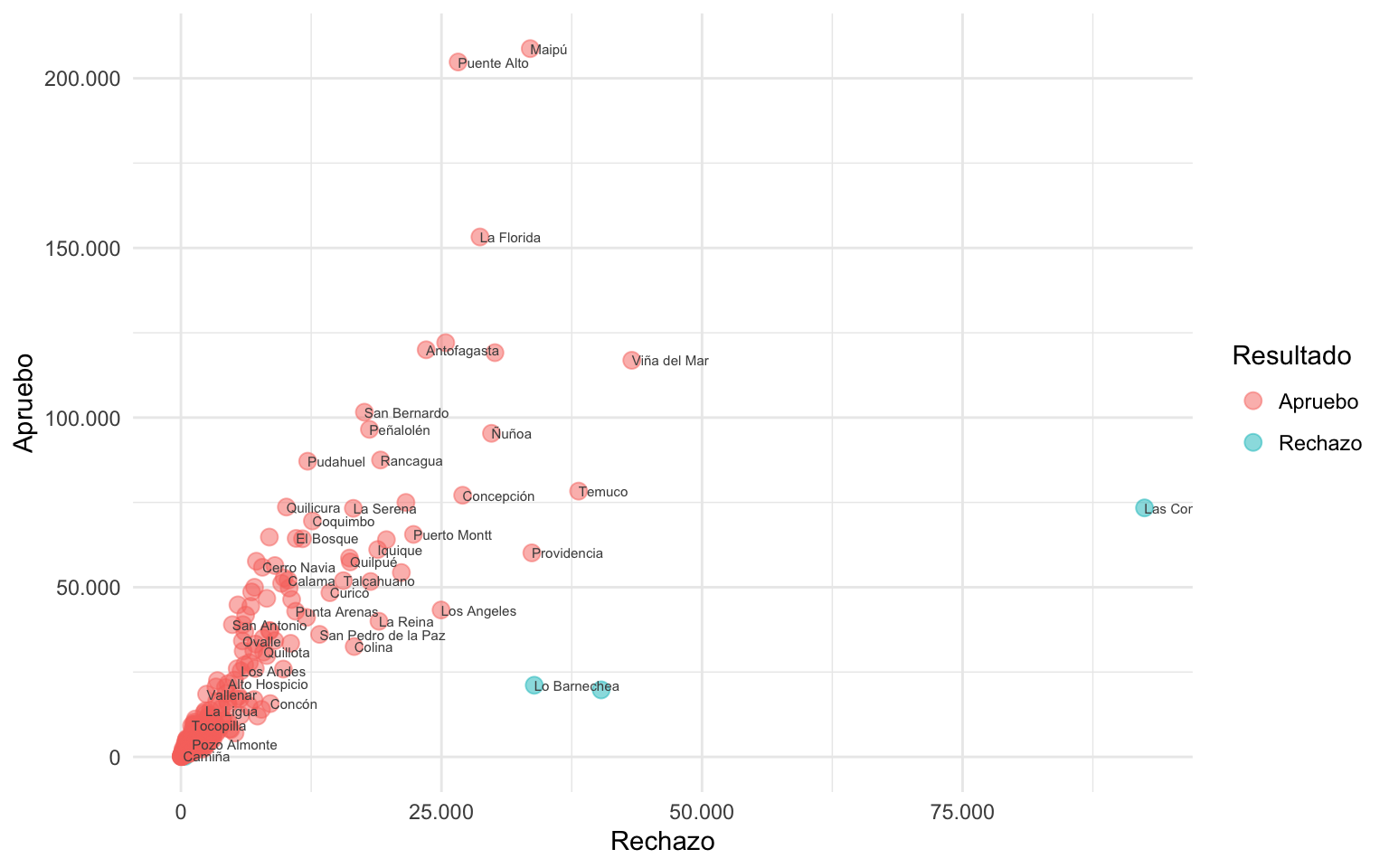
Esta función tiene varios argumentos para ajustar el algoritmo que decide la ubicación de los textos. Uno de ellos es max.overlaps, cuyo defecto es 10, y determina la cantidad máxima de etiquetas que pueden estar unas encima de otras antes de qué sean descartadas por estar demasiado concentrados en un mismo lugar. Si aumentamos este argumento, la función tomará en cuenta etiquetas de texto en ubicaciones más complejas, e intentará graficarlas moviéndolas más lejos de los puntos, o moviendo otras etiquetas de texto a posiciones más lejanas del punto que lo origina. Para mejorar el resultado, podemos aumentar el valor del argumento max.time, el cual le da más tiempo al algoritmo para buscar resolver el posicionamiento de los textos.
grafico_resultado +
geom_text_repel(aes(label = comuna), size = 2.5, color = "grey30",
segment.size = 0.1, # ancho de líneas (si es que salen)
max.overlaps = 30, max.time = 1)
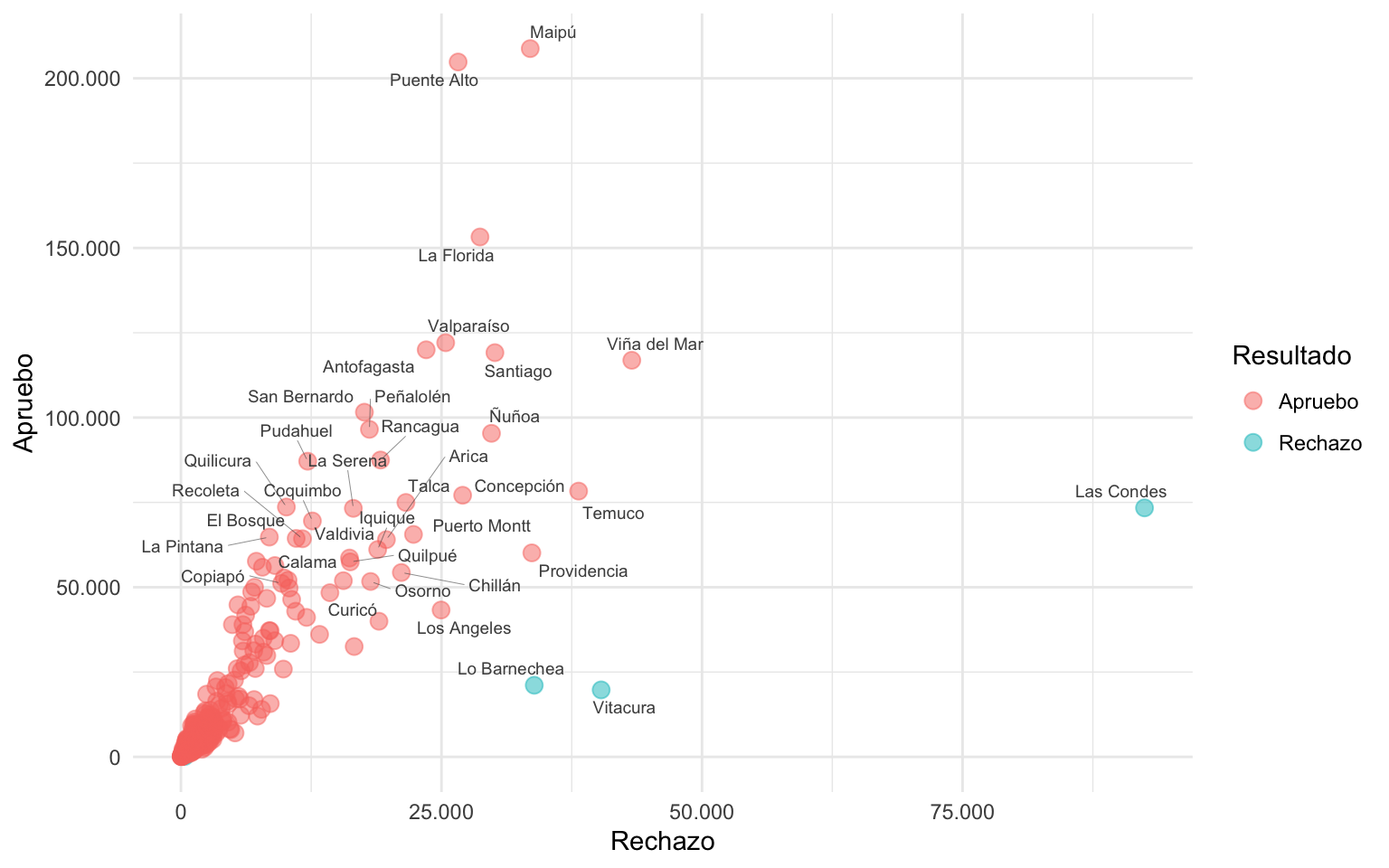
En el gráfico anterior, aparecen nuevas etiquetas que no salieron antes, algunas de ellas conectadas por líneas con el punto correspondiente.
También podemos determinar ciertos parámetros para que aparezcan o no aparezcan ciertos textos en el gráfico. En el siguiente ejemplo, agregamos una condicional para que solamente aparezcan textos que superen ciertos valores de cada eje, excluyendo los demás.
grafico_resultado +
geom_text_repel(aes(label = ifelse(rechazo > 30000 | apruebo > 100000, comuna, " ")),
size = 2.5, color = "grey30",
segment.size = 0, max.overlaps = 30)
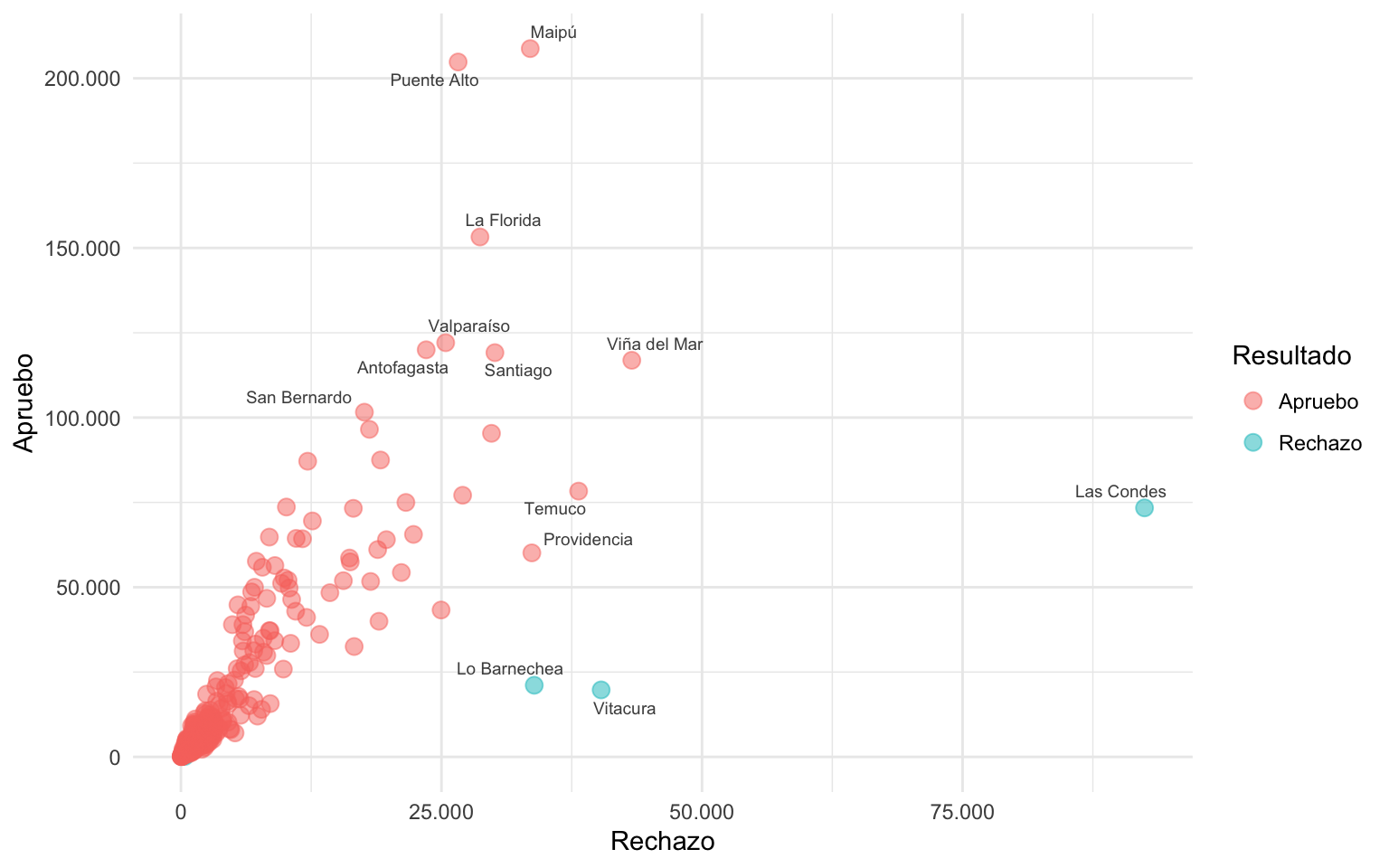
Es importante dejar las observaciones que queremos excluir de el etiquetado de texto con un texto vacío o un espacio (" "), y no solamente filtrar las observaciones del dataset, porque así los puntos del gráfico seguirán teniendo un texto vacío encima de ellos, lo que hará que el resto de las etiquetas de texto también se alejen de los puntos sin etiqueta.
Haremos un acercamiento al gráfico, definiendo los límites verticales y horizontales con coord_cartesian(), para que hayan puntos más dispersos:
grafico_resultado +
coord_cartesian(xlim = c(0, 10000),
ylim = c(0, 50000),
clip = "off") +
geom_text_repel(
aes(label = ifelse(rechazo > 3000 & rechazo < 10000
| apruebo > 20000 & apruebo < 50000,
comuna, " ")),
size = 2.5, color = "grey30",
segment.size = 0, max.overlaps = 30, max.time = 5)
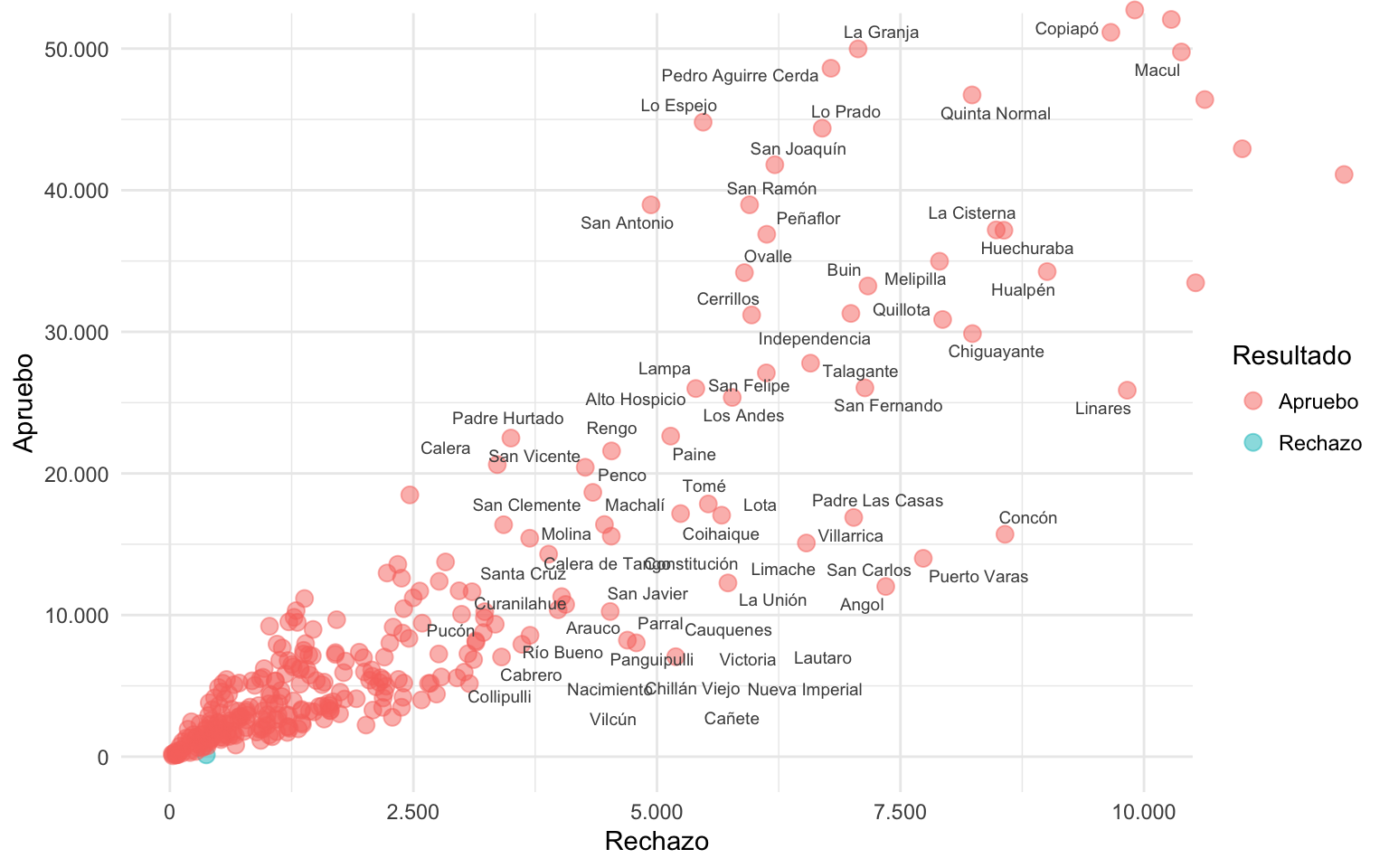
En este caso aplicamos condicionales más estrictas para que aparezcan o desaparezcan los puntos, con el objetivo de que aparezca la mayor cantidad de textos de un sector específico del gráfico.
También podemos utilizar criterios estadísticos para incluir o excluir el etiquetado de textos. Por ejemplo, en el siguiente gráfico solamente mostramos el nombre de los puntos cuyo valor es superior al percentil 73 de cada variable.
grafico_resultado +
geom_text_repel(aes(label = case_when(rechazo > quantile(rechazo, 0.73) ~ comuna,
apruebo > quantile(apruebo, 0.73) ~ comuna)),
size = 2.5, color = "grey30",
segment.size = 0, max.overlaps = 30, max.time = 5) +
scale_x_continuous(labels = label_number(), limits = c(0, 10000)) +
scale_y_continuous(labels = label_number(), limits = c(0, 30000)) +
labs(x = "Rechazo (detalle)", y = "Apruebo (detalle)")
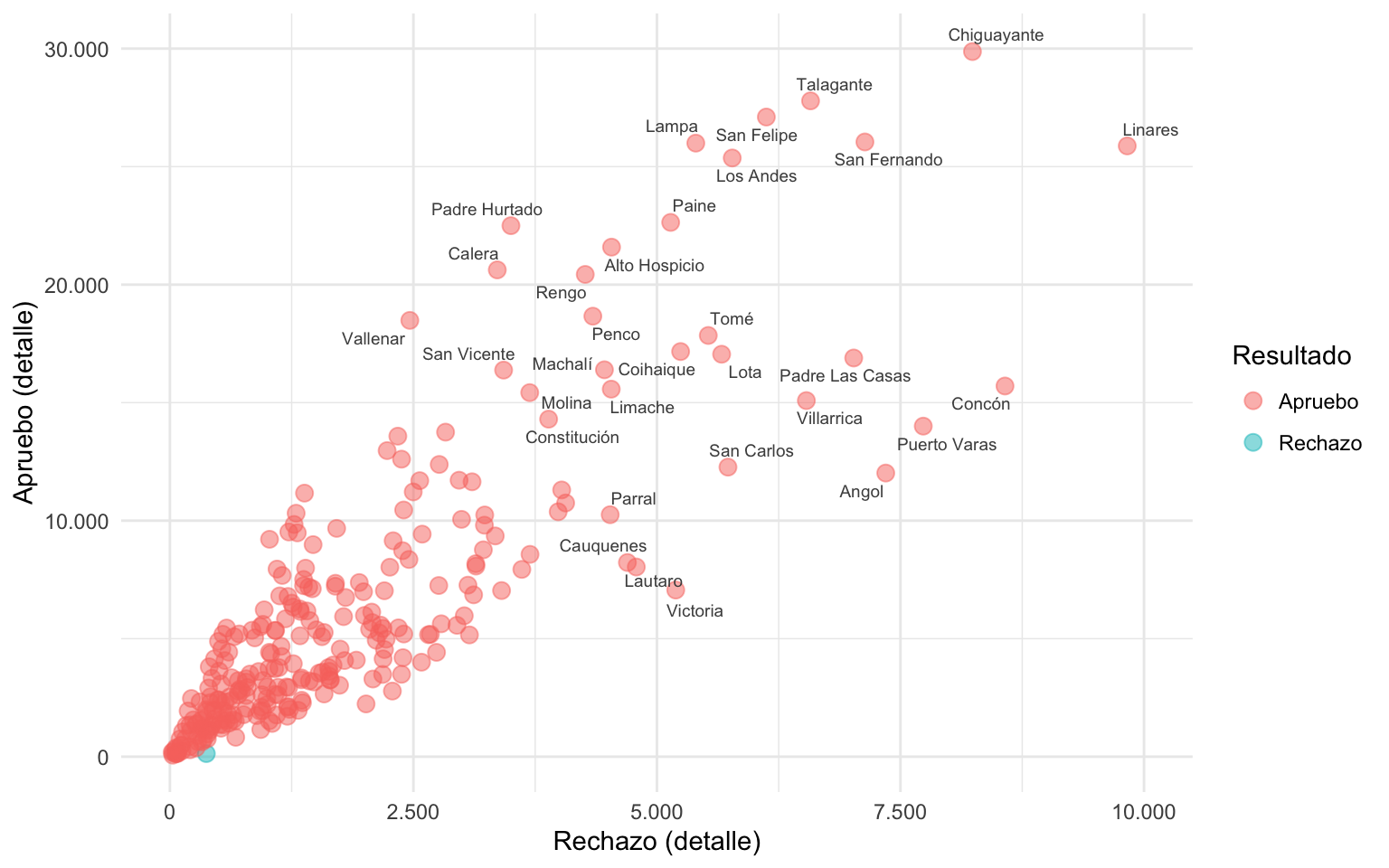
Gráfico interactivo
Finalmente, una mejor solución para estos casos sería permitir a las y los usuarios explorar la información de todas las observaciones del gráfico mediante la interactividad. El
paquete {ggiraph} para visualizaciones interactivas nos puede ayudar a transformar cualquier gráfico de {ggplot2} en un gráfico interactivo, donde los usuarios pueden tocar o poner el Mouse encima de un elemento para obtener más información. Sólo es necesario agregarle _interactive a las funciones geom_ del gráfico, y especificar el texto que aparecerá cuándo se ponga el cursor encima de cada elemento en tooltip dentro de aes():
library(ggiraph)
library(glue)
grafico_interactivo <- plebiscito_comunas |>
ggplot() +
aes(rechazo, apruebo, color = resultado) +
geom_point_interactive(size = 3, alpha = 0.5,
aes(tooltip = glue("<b>{comuna}</b>: gana {resultado} con un {percent(porcentaje, 0.1)}"))
) +
geom_text_repel(aes(label = comuna), size = 2.5, color = "grey30",
segment.size = 0.1, point.padding = 2) +
scale_x_continuous(labels = label_number()) +
scale_y_continuous(labels = label_number()) +
theme_minimal() +
theme(legend.text = element_text(margin = margin(l = 2))) +
labs(x = "Rechazo", y = "Apruebo", color = "Resultado")
Para que el gráfico se vea y funcione interactivamente, debemos mostrarlo mediante la función girafe():
girafe(ggobj = grafico_interactivo,
# dimensiones del gráfico
width_svg = 7, height_svg = 5,
# opciones para los tooltips
options = list(
# ocultar barra de opciones
opts_toolbar(hidden = "selection", saveaspng = FALSE),
# color al poner el cursor encima
opts_hover(css = "fill: white; stroke: black;"),
# personalizar la apariencia del tooltip
opts_tooltip(opacity = 0.7, use_fill = TRUE,
css = "font-family: sans-serif; font-size: 70%; color: white; padding: 4px; border-radius: 5px;"))
)
Vemos que en el gráfico anterior, podemos obtener información extra de cada observación tan sólo poniendo el cursor encima, lo cual amplía bastante las posibilidades de comunicación, por ejemplo, permitiendo saber información de los puntos de los sectores más densos, o agregando la información de otras variables del conjunto de datos, como el porcentaje.
Próximamente: ejemplos para aplicar {ggrepel} en mapas y otras visualizaciones geoespaciales.